目录
这次是做的目录树,想到这个可以和python的目录爬取结合起来用,就想着搞点好玩的,把网站的可见目录转化成树结构可视化
1.树的存储结构说明
由于没有对目录进行文件夹和文件的区分,所以结构体内容还是比较少的,h是树的高度,永远方便后面树的图形化
2.树的函数说明
2.1 函数概览

2.2 函数设计思路
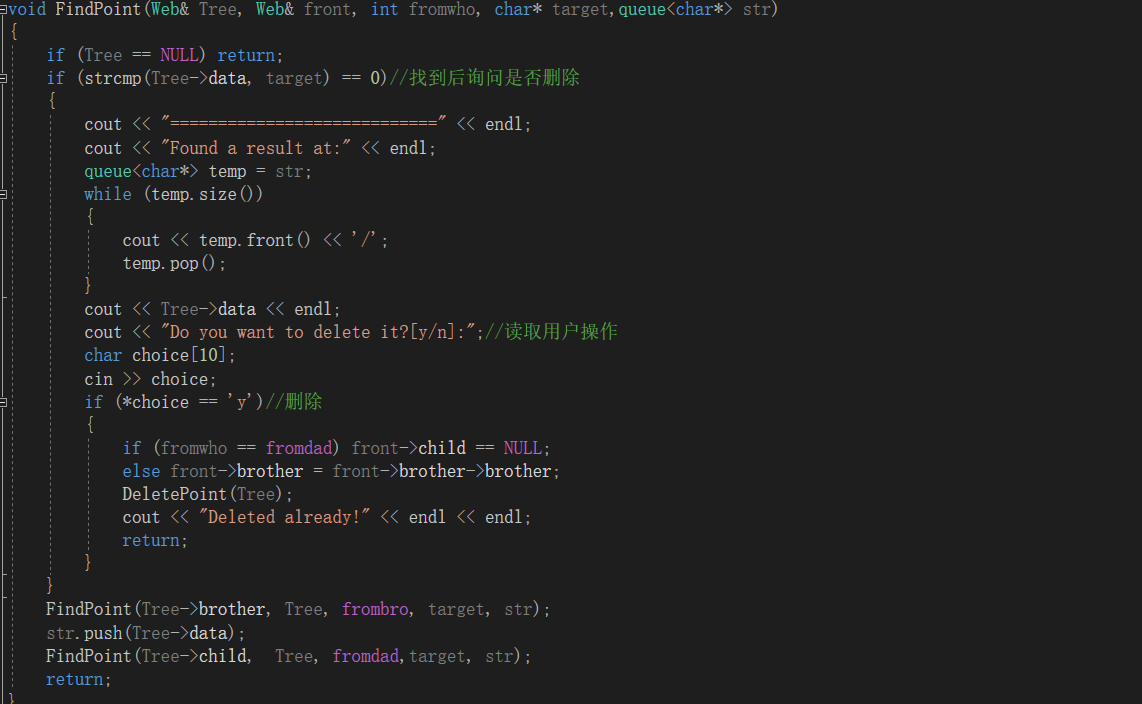
2.2.1 FindPoint函数
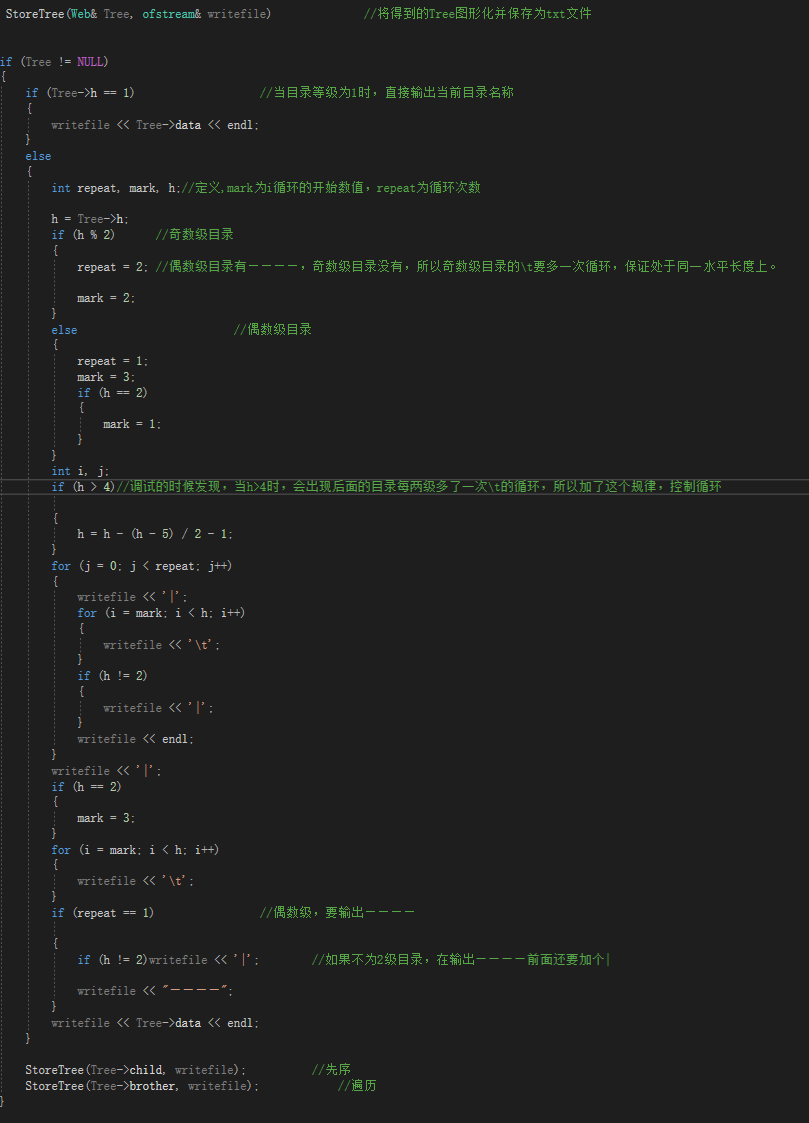
2.2.2 StoreTree函数
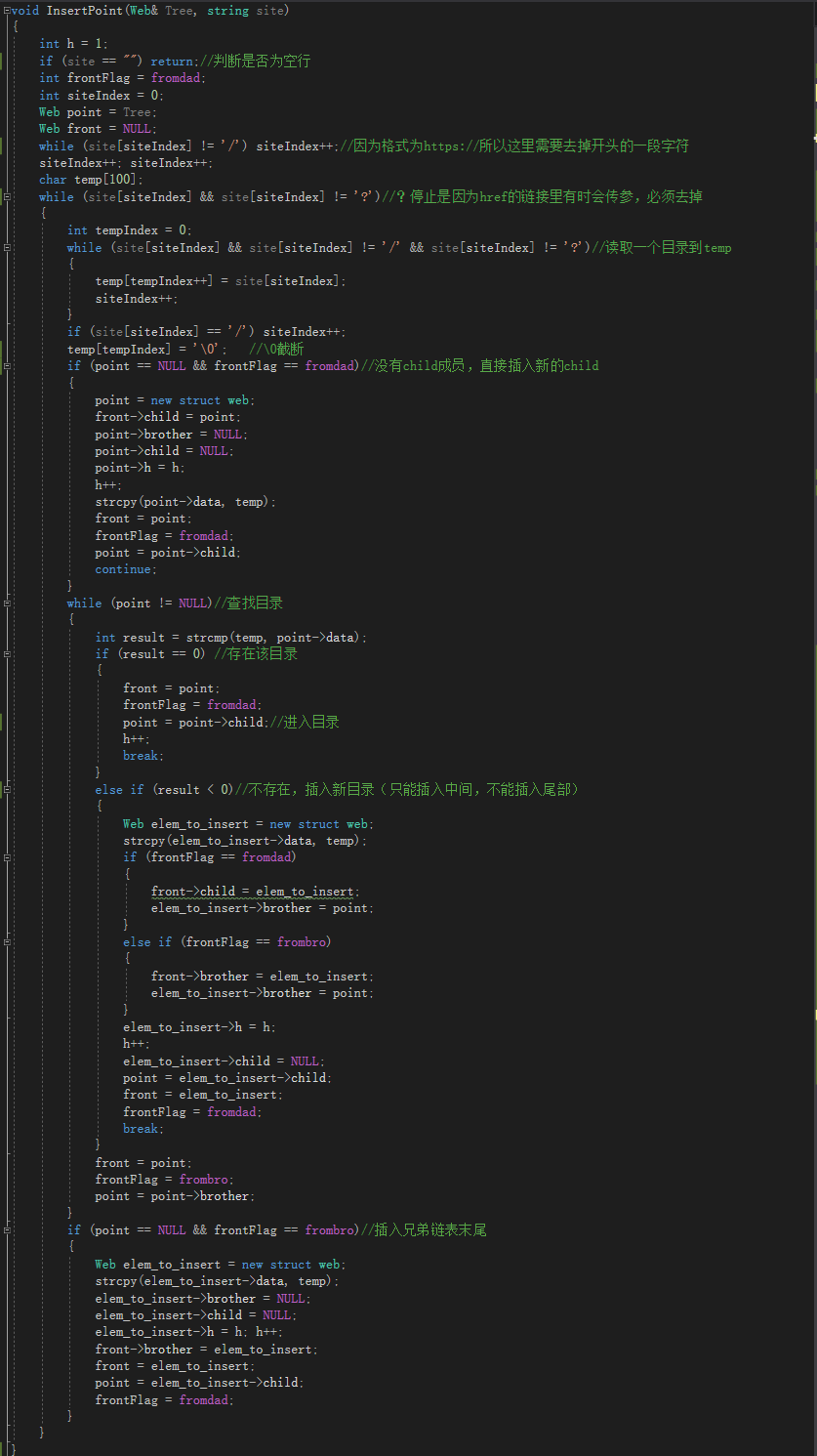
2.2.3 InsertPoint函数
2.2.4 Creat_RawData函数

2.2.5 DeletePoint函数
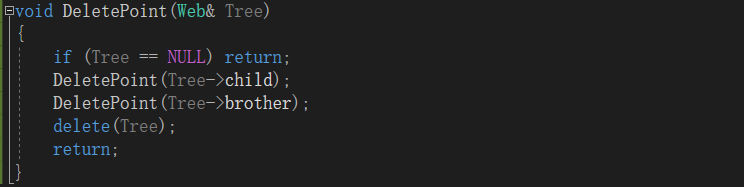
2.2.6 CreatTree函数
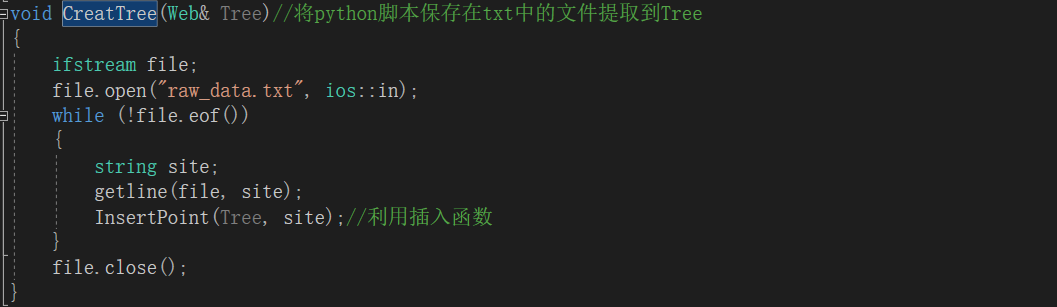
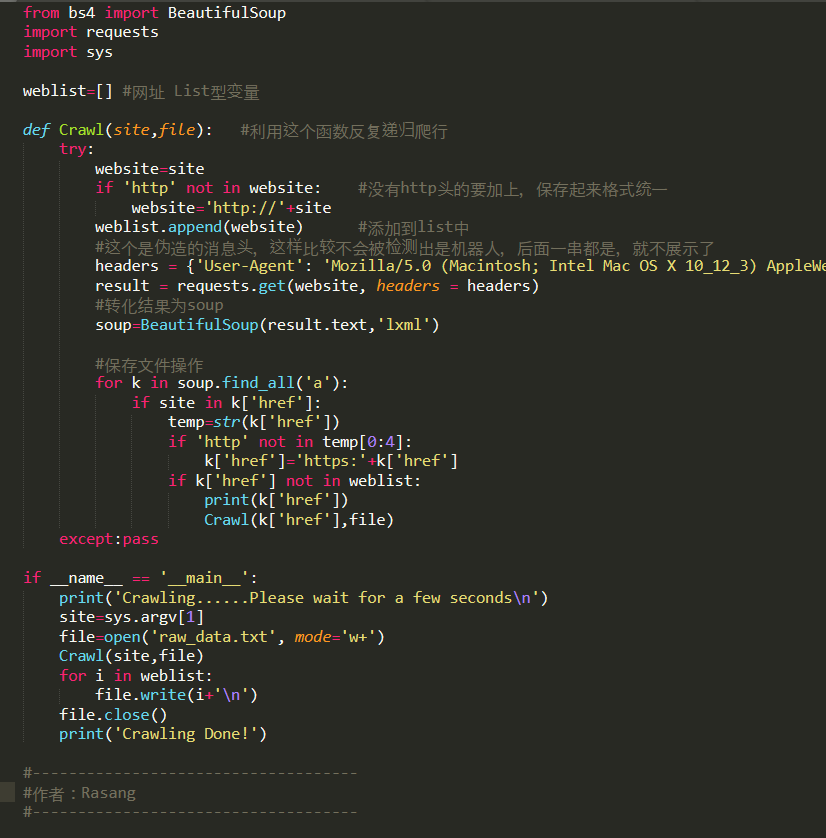
2.2.7 python脚本展示
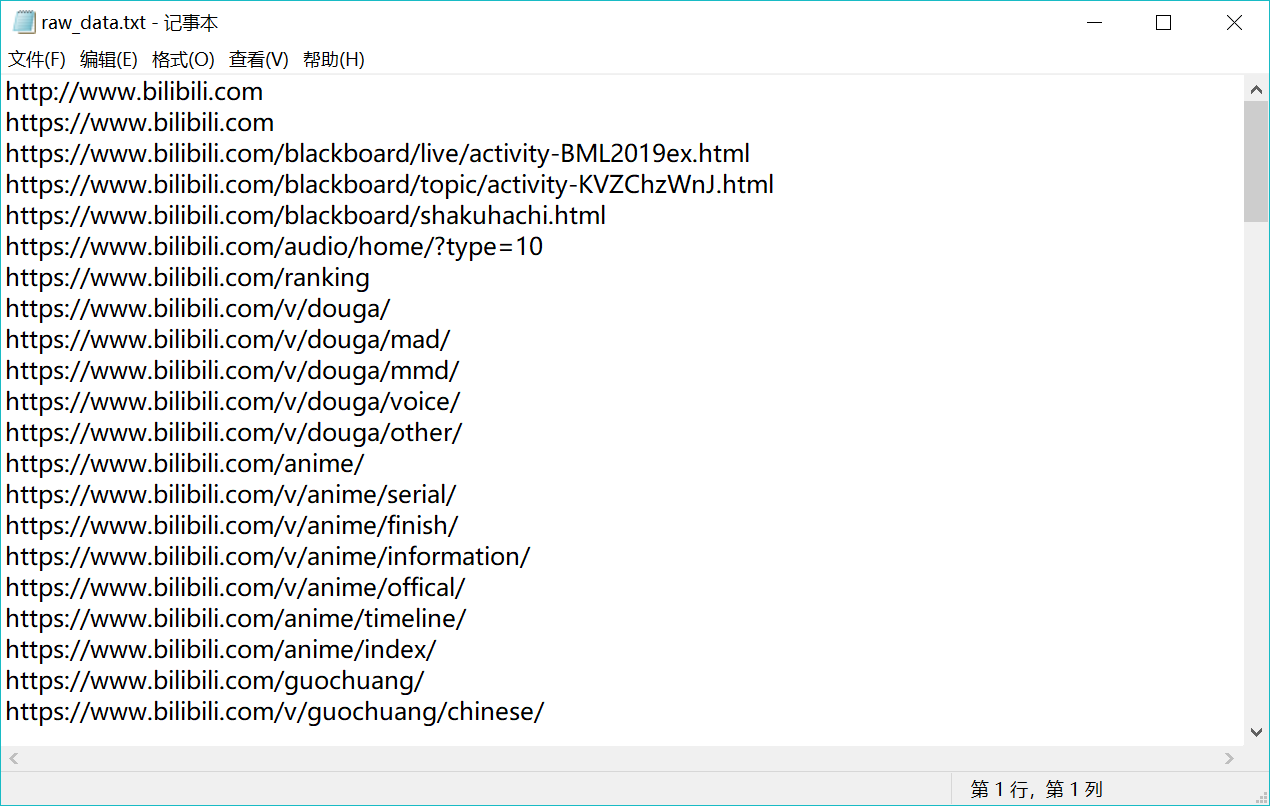
3.树结果演示
3.1 树生成展示

作者有话说:
3.2 插入删除展示
进入界面后用户需要输入一个网址用来爬行目录,结果会保存为txt也会展示在界面上
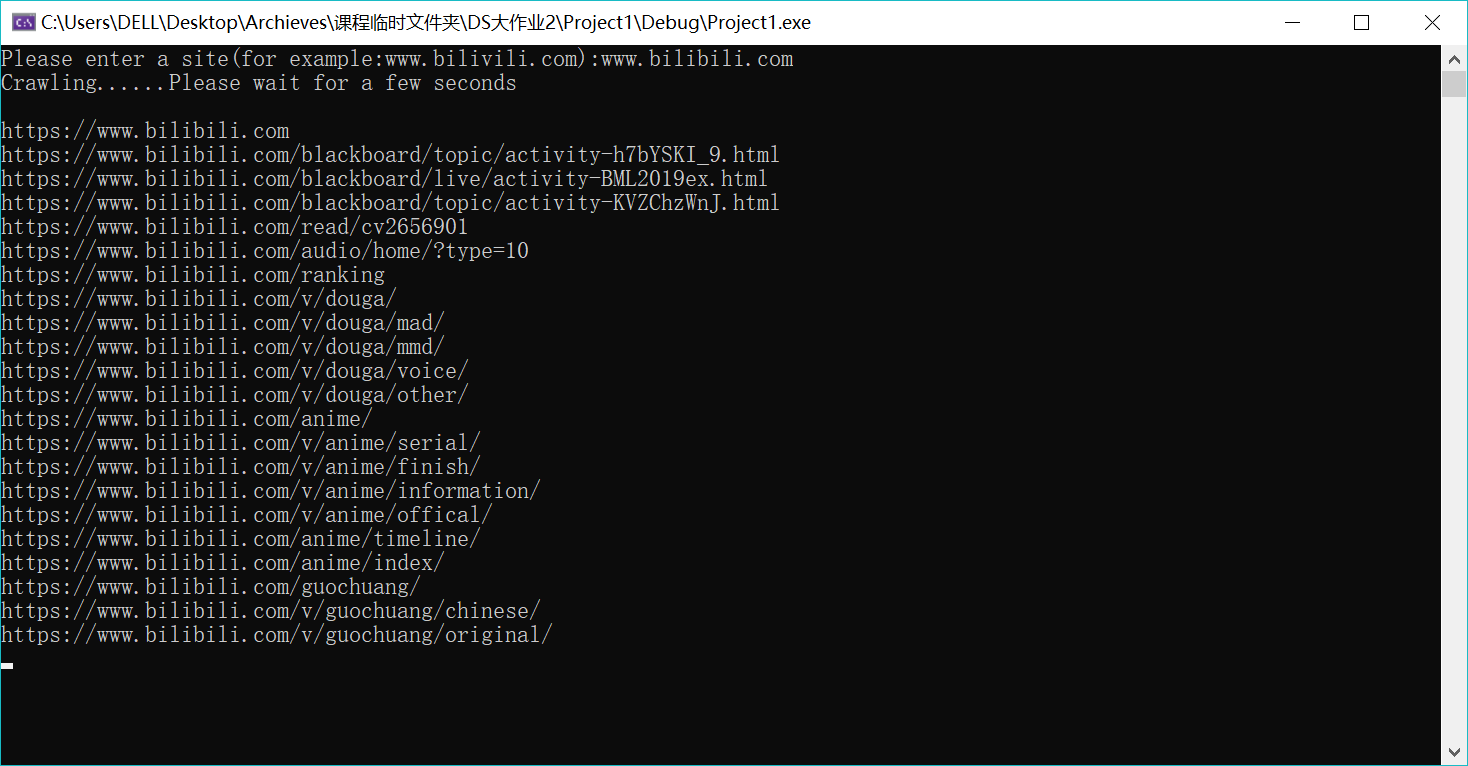
爬取网址结束后需要用户根据上面的结果输入要查找的目录名字,如果找到了会询问用户是否要删除这个目录,删除后使用StoreTree函数就可以将结果更新保存到txt图形化结果中
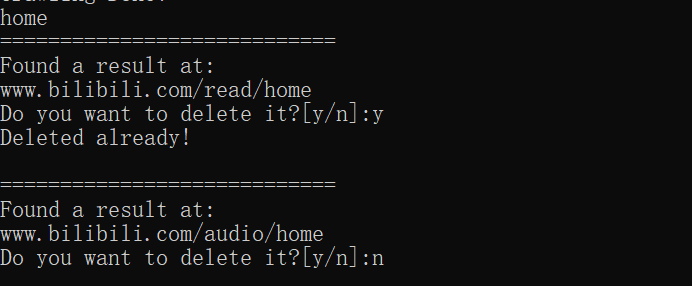
4.碰到问题
我遇到的问题:
问题一:python的bs4库不会用?
解决办法:百度搜索样例自己学
问题二:插入的时候怎么知道上一个节点是父母节点还是兄弟节点?
解决办法:宏定义fromdad和frombro,用来标记上一个节点是谁
问题三:在查找函数输出时输出异常?
如下:
 解决办法:在这里进行入队操作的时候不能使用先序的结构,否则路径是不对的,使用中序就可以解决,因为兄弟节点是不能直接入队的,只有孩子节点可以入队,这样才是一条路径
解决办法:在这里进行入队操作的时候不能使用先序的结构,否则路径是不对的,使用中序就可以解决,因为兄弟节点是不能直接入队的,只有孩子节点可以入队,这样才是一条路径 07遇到的问题
问题一:在StoreTree遍历写法上的选择
解决办法:考虑到函数有关乎文件的开关,因此一开始想通过非递归的形式进行遍历,但是代码比较赘余。最后选取递归的方法,并将文件的开关置外。
问题二:多级目录出现格式错误
解决办法: 为了使函数更具弹性,即函数适用对象更广泛,要找到一个合适的数学逻辑关系进行格式控制。通过调试,并且增加条件判断语句控制格式。
5.小结
先来说说缺点:一个是在处理文件的时候没办法把文件和文件夹分开,这就导致要看后缀名来判断是不是文件夹。还有一个就是老师在最后展示课上说的,最后将结果输出到文件里面的时候重复地写入文件影响效率,在课上听老师说可以保存到同一个string类型变量里面的时候我才恍然大悟,string类型很灵活,大小不受限制,只要把所有语句都加进去,把回车也加进去,就可以实现一次性写入,这点我是真的没有想到。
再来说说好的地方:自我觉得比较好的一个地方是设置了fromdad和frombro的宏定义,用来区分插入和删除时上一个节点的类型,方便将后继置为NULL。
6.小组成员分配说明
谢晓淞:
陈玲清:
参与内容:StoreTree函数的实现。 最终得分:罗小川:
参与内容:DeletePoint函数的实现,展示PPT的制作。 最终得分:霍淏华:
参与内容:将插入和查找的过程用动画演示出来,方便同学理解。 最终得分:鲁俊文:
参与内容:测试bug。理解代码 最终得分:岳小钢:
参与内容:测试bug。理解代码 最终得分:介绍小组成员、参与内容、贡献度、最后得分
7.展示你们讨论的照片
